Visually Grounded Continual Learning of Compositional Phrases
Xisen Jin, Junyi Du, Arka Sadhu, Ram Nevatia, Xiang Ren, EMNLP 2020 (To appear).
Overview
VisCOLL proposes a problem setup and studies algorithms for continual learning and compositionality over visual-linguistic data. In VisCOLL, the model visits a stream of examples with an evolving data distribution over time and learn to perform masked phrases prediction. We create COCO-shift and Flickr-shift (based on COCO-captions and Flickr30k-entities) for study. Check our data explorer for more details.

Study of Continual learning
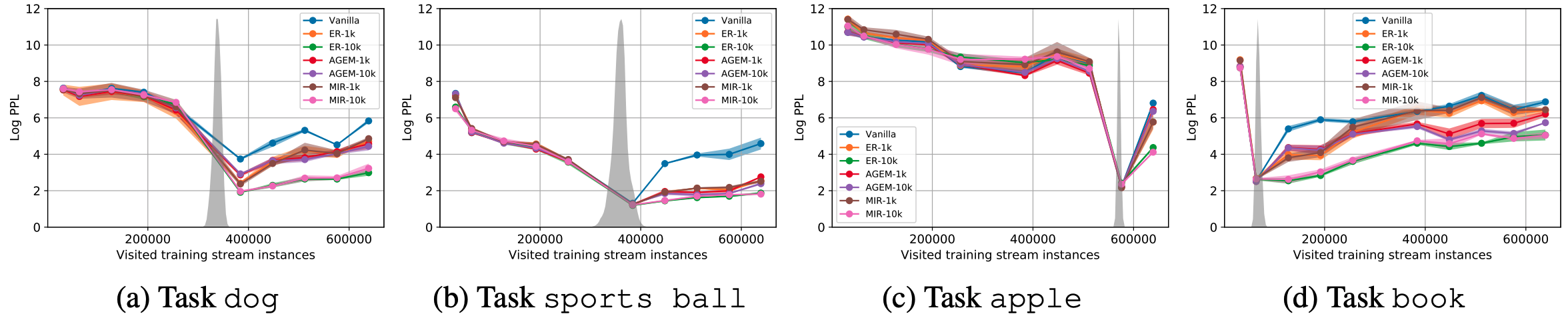
Vanilla training over an evolving data stream causes catastrophic forgetting of previous knowledge - continual learning (CL) algorithms are required for success in VisCOLL. Besides, in VisCOLL, data distributions evolve gradually over time and we assume no knowledge of task identity (which is closer to the real-world scenario), the continual learning algorithms should not rely on "task boundaries" or "task identities". We find VisCOLL is challenging for existing continual learning algorithms. The figure below compares CL algorithms, exemplified with four tasks: x-axis is the number of training examples visited and y-axis is the perplexity. The gray-shaded regions show the task distribution in the stream. We show existing CL algorithms do not differ significantly in performance given an equal size of replay memory. Check our Leaderboard for more information.
Study of Compositionality
Generalization to novel compositions - Compositonal Generalization
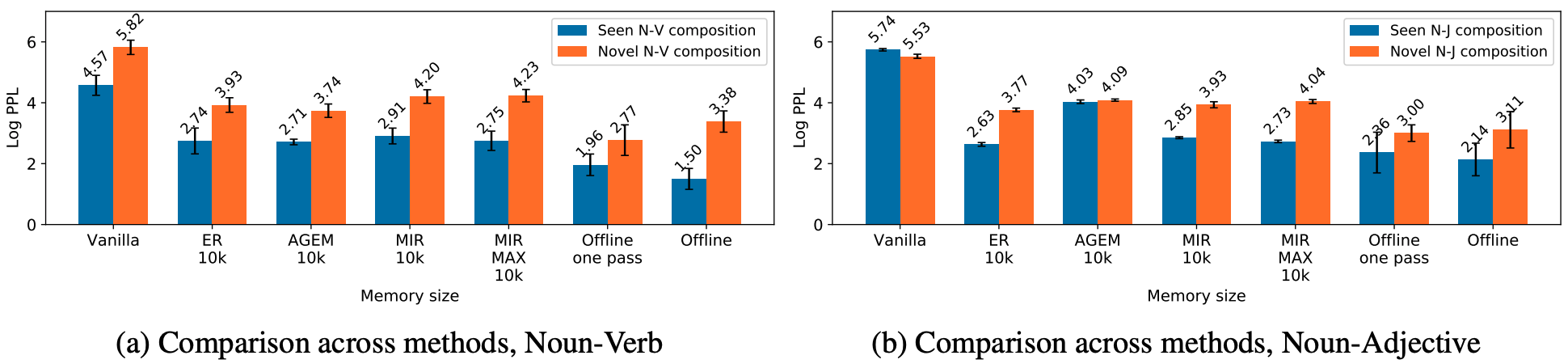
To measure compositionality captured by models, in addition to a regular test set, we evaluate model performance on the compositional test split of COCO-captions dataset by Nikolaus et al. 2019, which consists of novel noun-adjective and noun-verb pairs. We compare this performance with that of seen compositions sharing the same set of atomic words in the regular test set. Our methods show compositional generalization is challenging for all methods. The figure below shows the perplexity of seen and novel noun-verb and noun-adjective compositions compared between methods.
Performance on old seen compositions
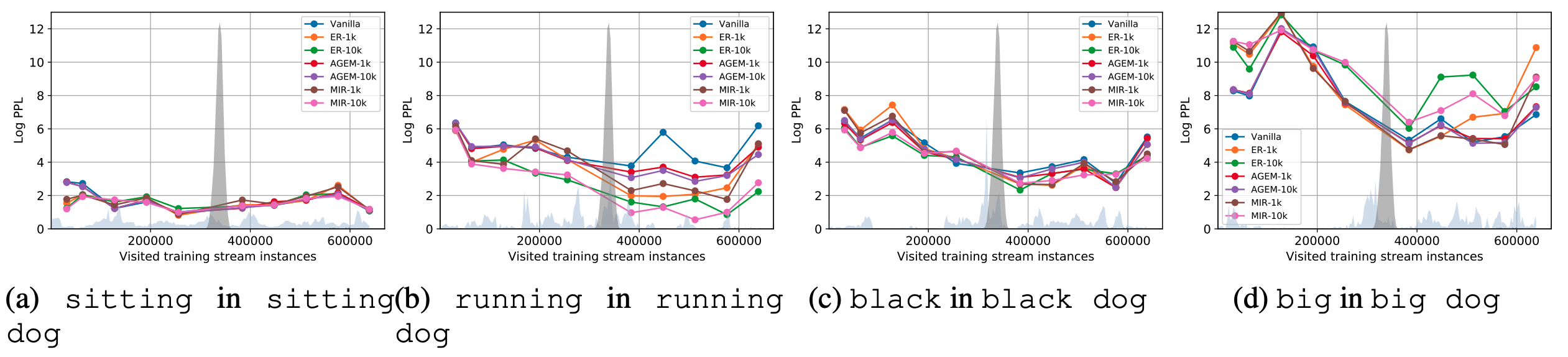
We study performance on compositions sharing the same nouns but with different verbs/adjectives. Our analysis shows the performance drop largely depends on the verbs/adjectives used in the compositions, despite their marginal distributions are close to uniform over time. In the figure below, x-axis is the number of training examples visited and y-axis is the perplexity (lower is better) of the verb/adjective. The sharp gray-shaded regions are for the noun, while the light-blue regions near x-axis are for the adjectives. The performance drop on predicting “black” in the composition “black dog” is relatively small compared to predicting “big” in “big dog”.
To cite us
@inproceedings{Jin2020VisuallyGC,
title={Visually Grounded Continual Learning of Compositional Phrases},
author={Xisen Jin and Junyi Du and Arka Sadhu and R. Nevatia and X. Ren},
booktitle={EMNLP},
year={2020}
}