Overview
Event forecasting is a challenging, yet important task, as humans seek to constantly plan for the future. ForecastQA aims to formulate a task, construct a dataset, and provide benchmarks for developing methods for event forecasting with large volumes of unstructured text data. We create a question-answering dataset consisting of 10,392 event forecasting questions, which have been collected and verified via crowdsourcing efforts. Check our data explorer for more details.
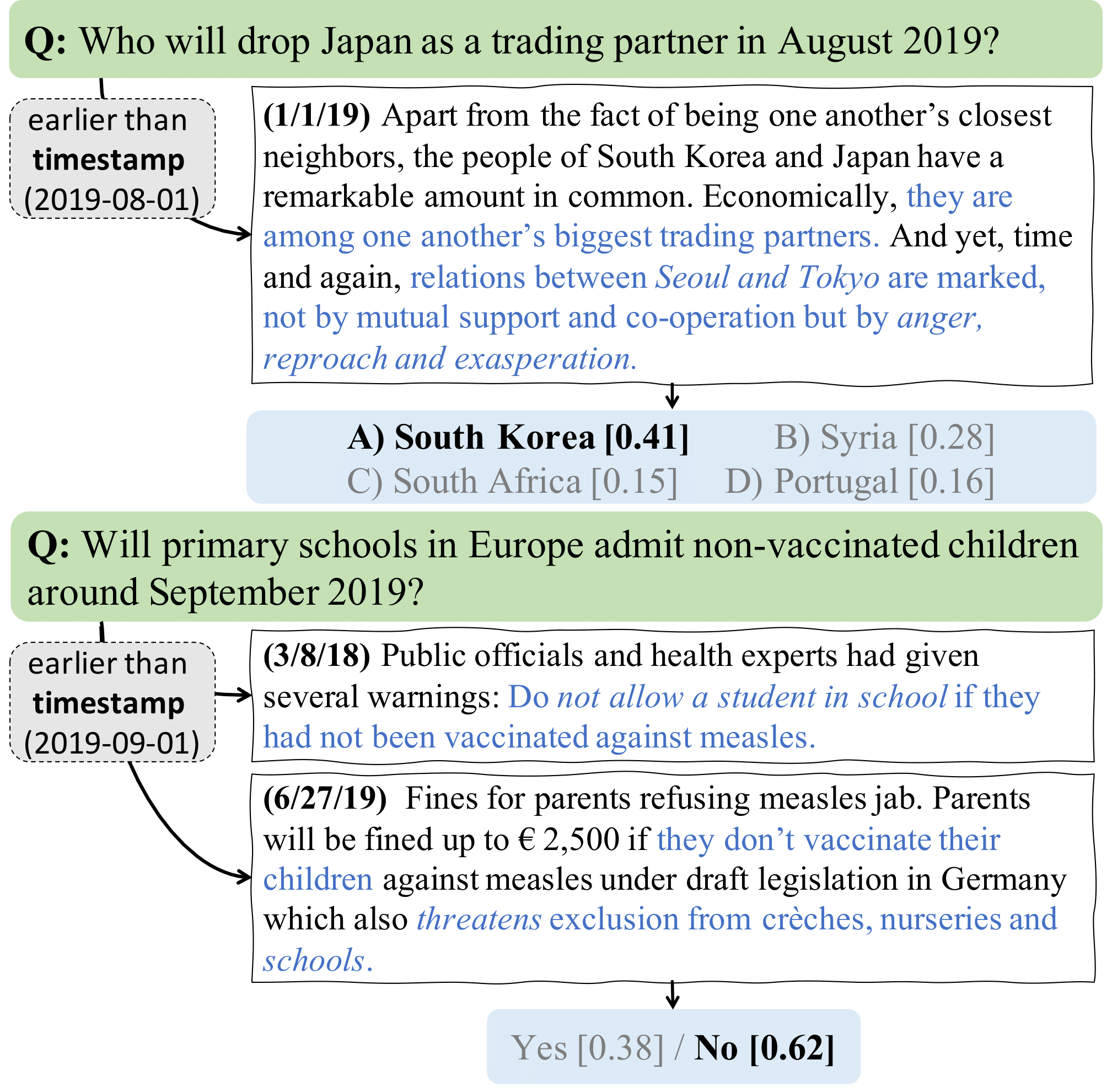
Task Definition
Formally, the input of the ForecastQA task is a forecasting question with a corresponding ending timestamp ––the last possible date where the question remains a forecasting question. In addition, we have a set of possible choices, and a corpus of news articles; the output is a choice. Our task has a novel time constraint that any retrieved article must satisfy the condition that the retrieved article should be published before the time constraint. In other words, models only have access to articles that are published before the time constraint.
Challenges
Due to the constrained open-domain setting and forecasting properties, our task encompasses the following challenges: information retrieval (IR) on limited sources, extraction and understanding of casual and temporal relations between events, and finally a forecasting judgement. Our novel constraint limits the accessible information and thus makes our task more challenging than standard QA; new IR methods are necessary to anticipate what knowledge will be useful for predictions from past information sources. Once useful articles have been retrieved, models should understand the retrieved articles and extract pertinent facts from them. Finally, they use the gleaned knowledge to infer the outcome of a future event. Unlike in other tasks, models cannot rely on the existence of an answer within the text, but must make an educated guess as to what will happen in the future.
Dataset Construction
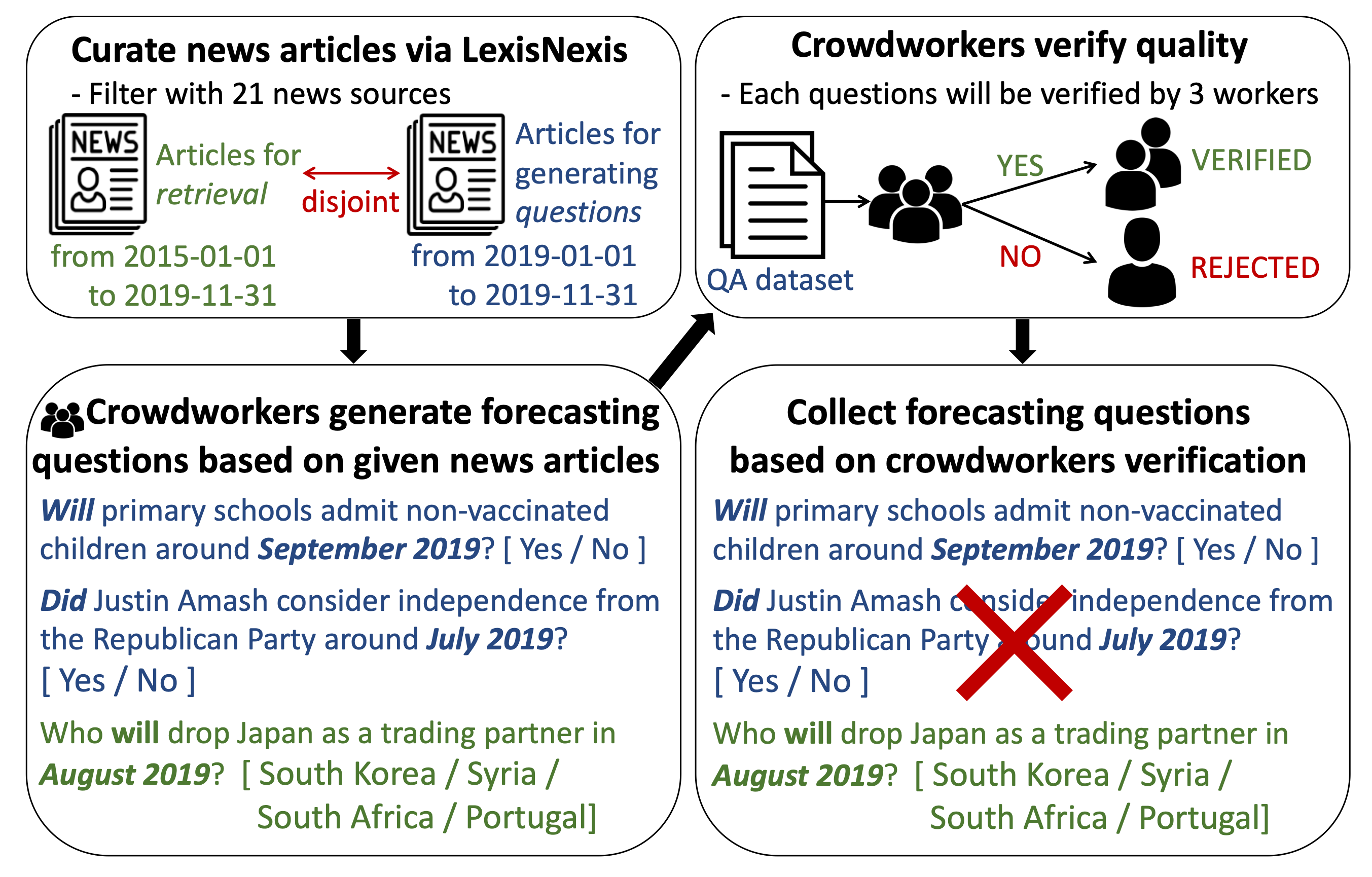
we collected our dataset to support ForecastQA, broken down into three sections (1) gathering a news corpus, (2) generating question-answer-timestamp triples with distractor choices, (3) verifying triple quality, and (4) collecting appropriate questions.
To cite us
@article{jin2020forecastqa,
title={ForecastQA: A Question Answering Challenge for Event Forecasting with Temporal Text Data},
author={Jin, Woojeong and Khanna, Rahul and Kim, Suji and Lee, Dong-Ho and Morstatter, Fred and Galstyan, Aram and Ren, Xiang},
booktitle={arXiv preprint arXiv:2005.00792},
year={2021}
}






