MickeyProbe: A Multilingual task for probing commonsense knowledge and analysis.
Table of contents
Download the MickeyCorpus for MickeyProbe
Motivation
We present MickeyProbe, a Multilingual task for probing commonsense knowledge and analysis. We design a language-agnostic probing task with a sentence-selection objective for analyzing common sense of a ML-LM: given a set of assertions (i.e., declarative sentences) that have similar words and syntactic features, select the one with highest commonsense plausibility. Simply put, one can see MickeyProbe as a multilingual, constrained version of the LAMA probe task for analyzing the commonsense knowledge in multilingual language models.
Task Formulation

Given a Micky Probe \({M}\) in the dataset \(\mathcal{M}\), and suppose the index of the truth assertion to be \(t\), a perfect multilingual language model would produce sentence probabilities such that it always gives the truth assertion \({M}^l_t\) (in language \(l\)) the highest probability among other candidates for every language: \(\forall l\in \mathcal{L}, \forall i\in \mathbb{N}_{\leq K},~ P({M}^l_i) \leq P({M}^l_t).\) Thus, our evaluation metric is the hit@k accuracy. Here is a specific example from our MickeyCorpus data.
There are two key advantages of the MickeyProbe: (1) The sentence-level probability can be more generally applied in languages besides English, comparing with the LAMA probe which only studies single-token English words. (2) The task formulation creates a relatively closed-ended setting, such that we can use a language-independent evaluation metric to fairly compare across various languages within an ML-LM and compare across various ML-LMs for a particular language. Please see Section 3 of our paper for more details.
MickeyCorpus
We construct a multilingual commonsense knowledge corpus, MickeyCorpus, for probing and analyzing ML-LMs via the MickeyProbe task.
We has has 561k sentences in 11 languages ({en, es, nl, de, fr, zh, it, ru, bg, vi, hi}), where each probe has 5 sentence candidates — i.e., \(T=10.2k, K=5, |L|=11\) in the above figure.
The MickeyCorpus is constructed on top of the OMCS corpus via adversarial distractor generation and machine translation.
Please download the corpus here
. We show a particular probe (in en and zh respectively) here:
# a line in "mickey_en.jsonl"
{
"id":"0c367b08c090925c",
"lang":"en",
"probes":[
"You can plan a coin cap wallet to carry all your credit cards .",
"You can use a credit card wallet to log all your credit cards .",
"You can use a credit card wallet to carry all your credit cards.", # correct
"You can load a credit card wallet to carry all your credit cards .",
"You can plug a credit card wallet to carry all your credit cards ."
],
"truth_id":2
}
# a line in "mickey_zh.jsonl"
{
"id": "0c367b08c090925c",
"lang": "zh",
"probes": [
"你可以计划一个硬币盖钱包 携带所有的信用卡。",
"您可以使用信用卡钱包登录您的信用卡 。",
"您可使用信用卡钱包携带您的信用卡。", # correct
"你可以装上信用卡钱包 携带所有信用卡",
"您可以插入信用卡钱包,携带所有信用卡。"
],
"truth_id": 2
}
Analysis Results
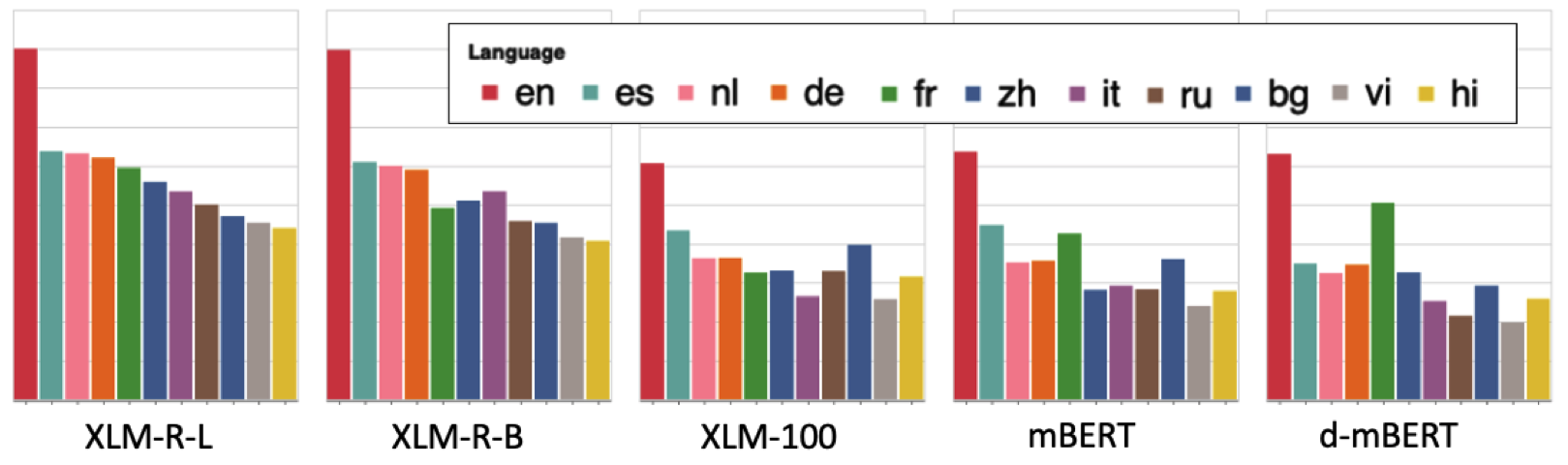
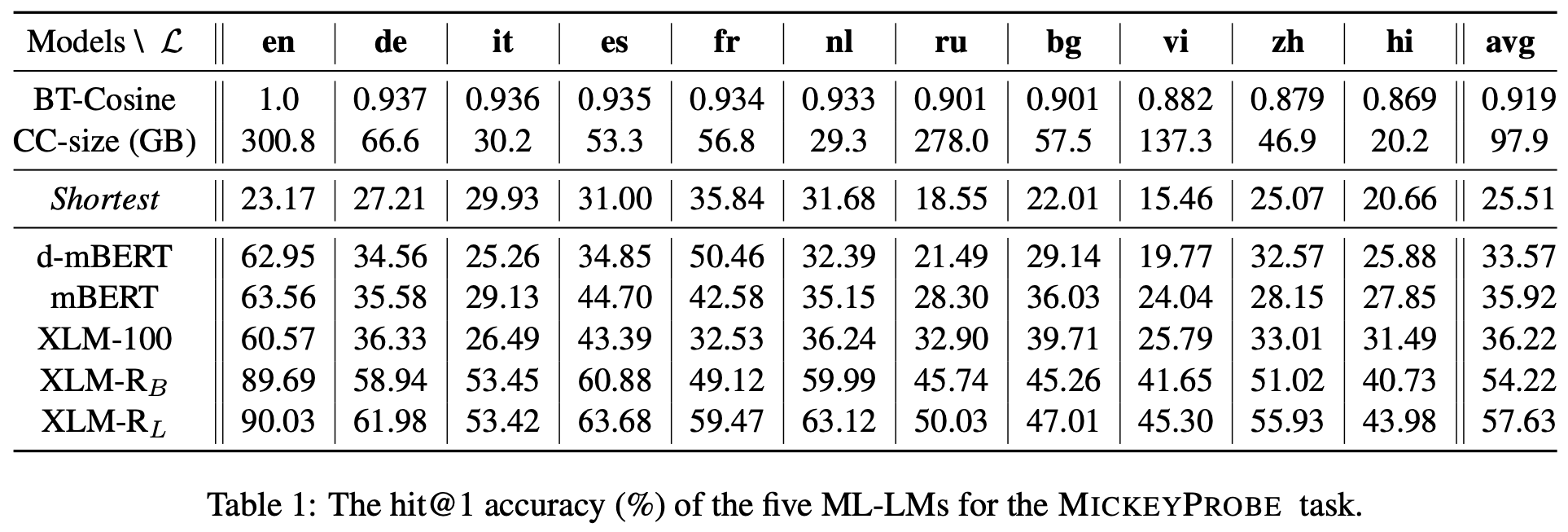
Sentence Scoring. For naturally inducing sentence scores from a masked ML-LM, we use the pseudo-log-likelihood (PLL) following the mlm-scoring paper. Although we mainly studied the mask-based ML-LMs (e.g., mBERT, XLM, XLM-R), the MickeyProbe task itself is not limited.
More Findings. Please check more in our paper.
Usage for Multi-lingual Contrastive Pre-training See more details in our paper and the code here.