About LEAN-LIFE
We introduce an open-source web-based Label Efficient AnnotatioN framework for sequence labeling and classification tasks.
Our framework enables annotator to provide labels for a task, but also enables LearnIng From Explanations for labeling
decision with an easy-to-use UI.
LEAN-LIFE differentiates itself from other frameworks in these ways:
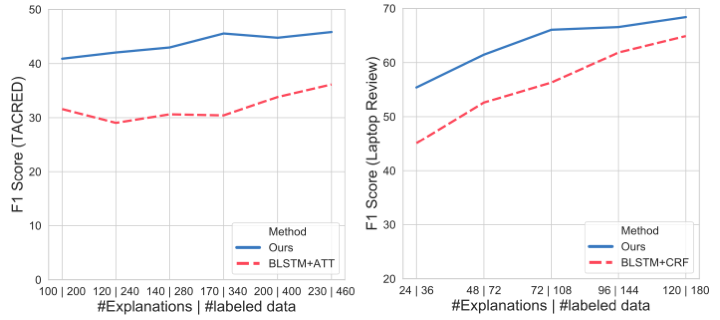
- Improved Model Training: Leveraging annotator-provided-explanations to weakly label unlabeled instances, our framework is able to train models with less data-points and improve model performance; hence reducing future annotations costs via better recommendations.
- Multiple supported tasks: We support both sequence labeling (named entity recognition) and sequence classification (relation extraction, sentiment analysis) tasks. All tasks can incorporate our improved model training if the annotator wishes so.
-
Explanation dataset creation: We enable the building of a new type of dataset,
one that consists of triples of: text, labels, and labeling explanations.
We have shown improvements on common NLP tasks using these triples and hope the community will
build upon our work by utilizing these triples.
We support two forms of explanation capture:
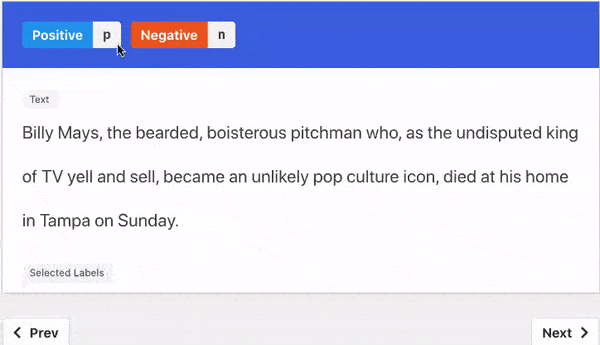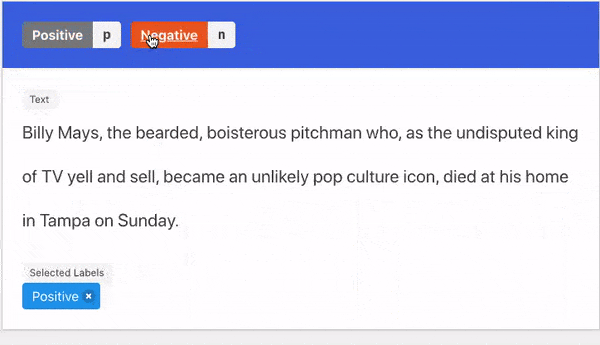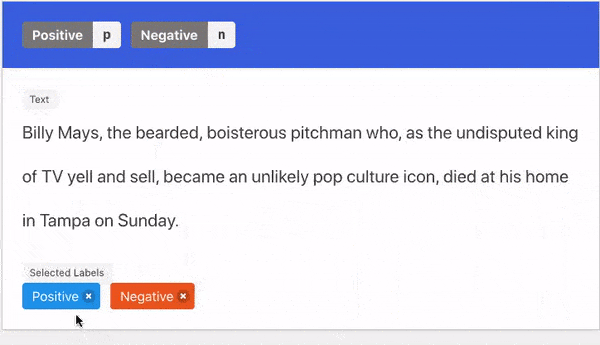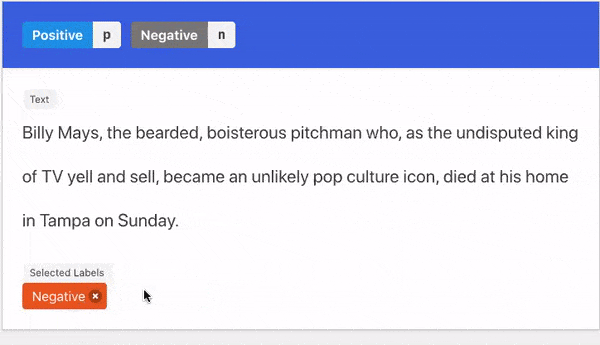
- Natural Language: guided written explanations that aided the labeling decision.
- Triggers: groups of words in a sentence that aided the labeling decision..
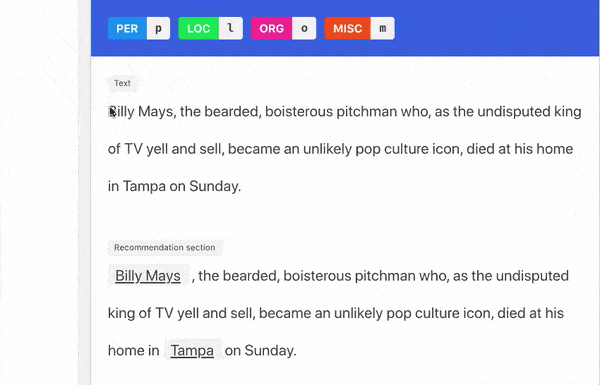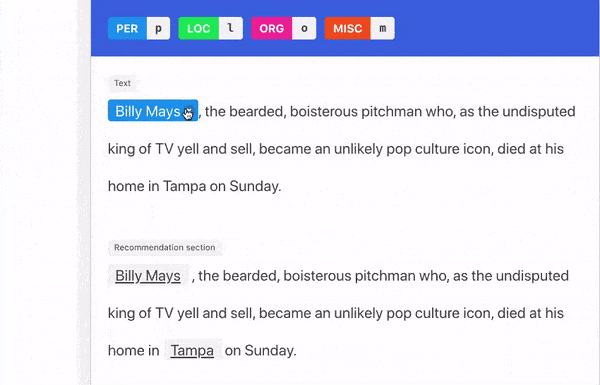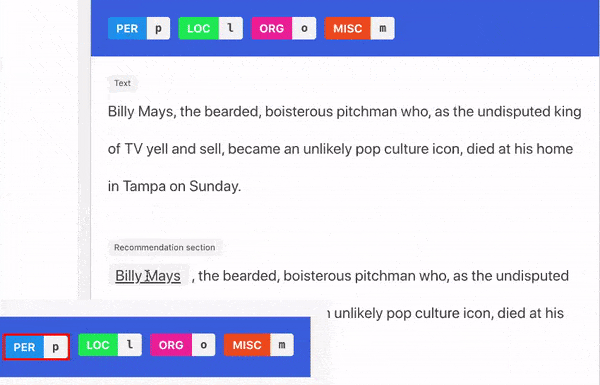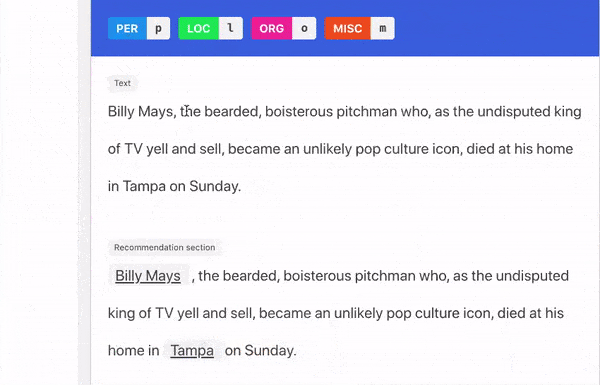
Two Kinds Of Explanations
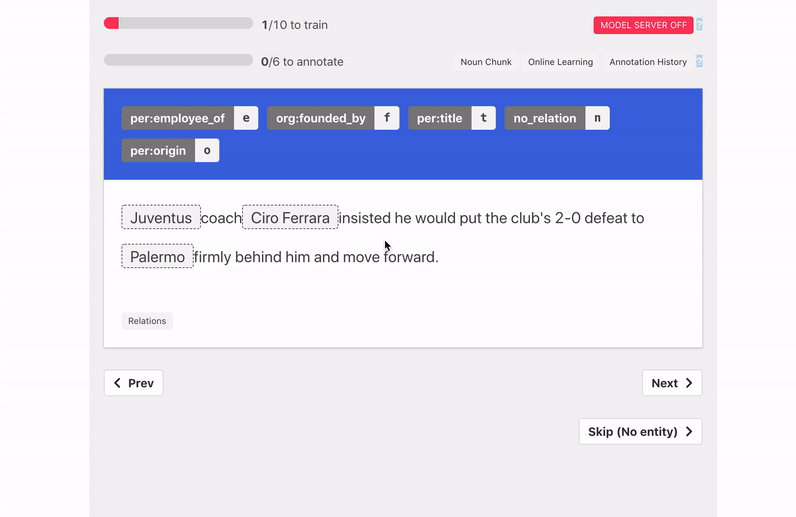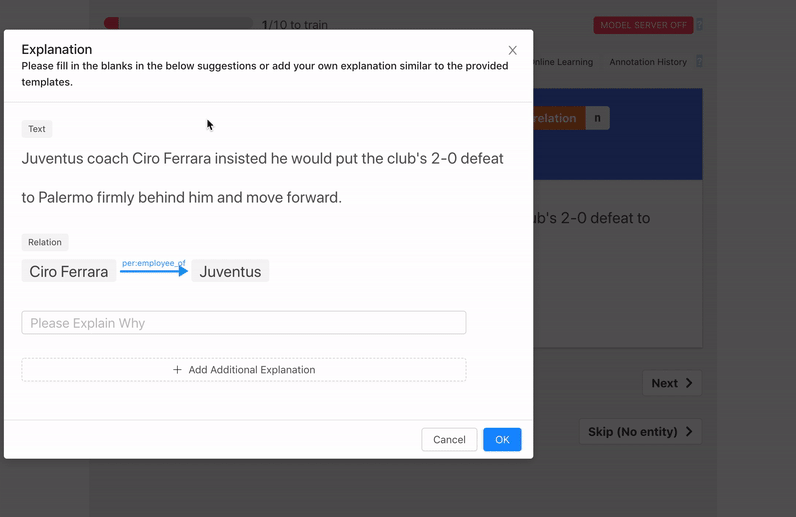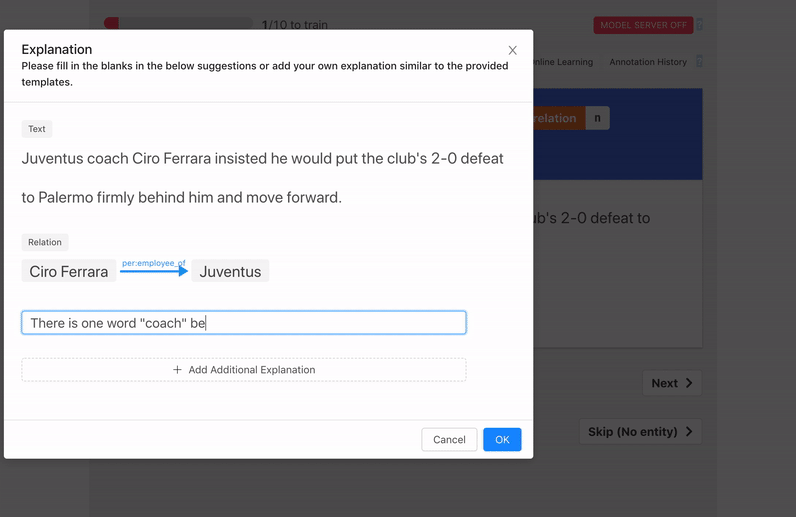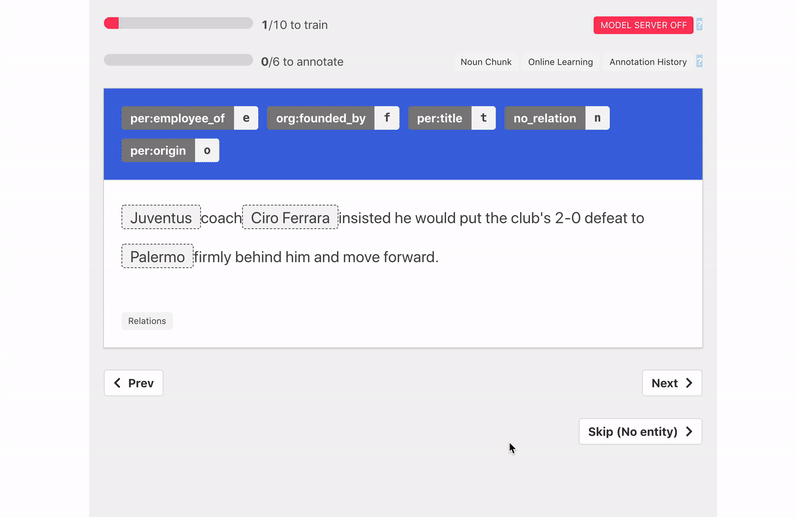

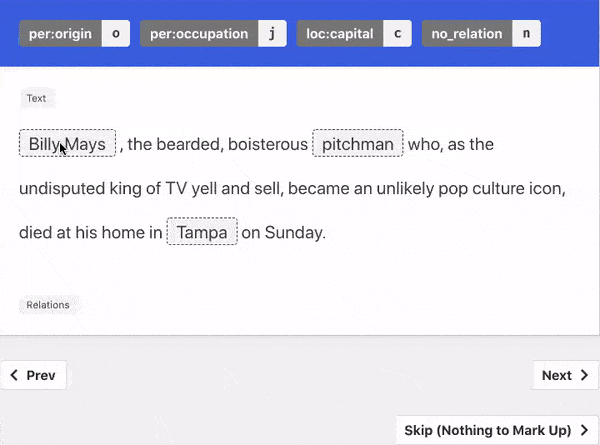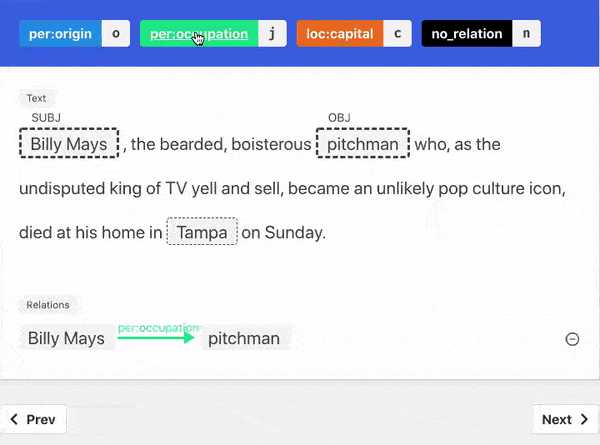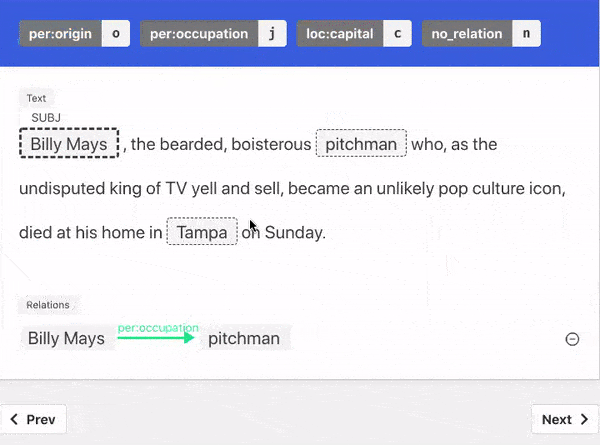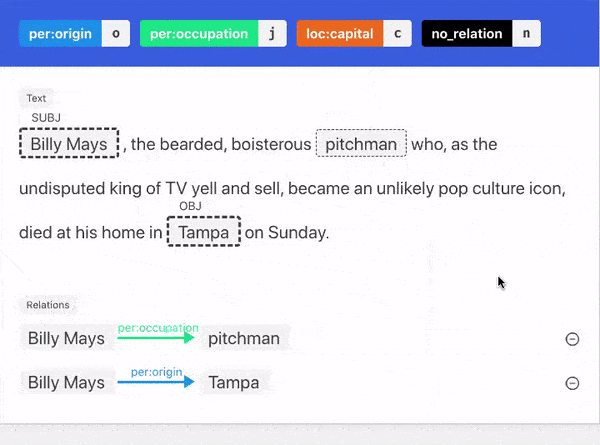
Similarly in the Sentiment Analysis example, because the word fair appears just before the word price we can weakly label the sentence "Delicious food with a fair price" as positive.
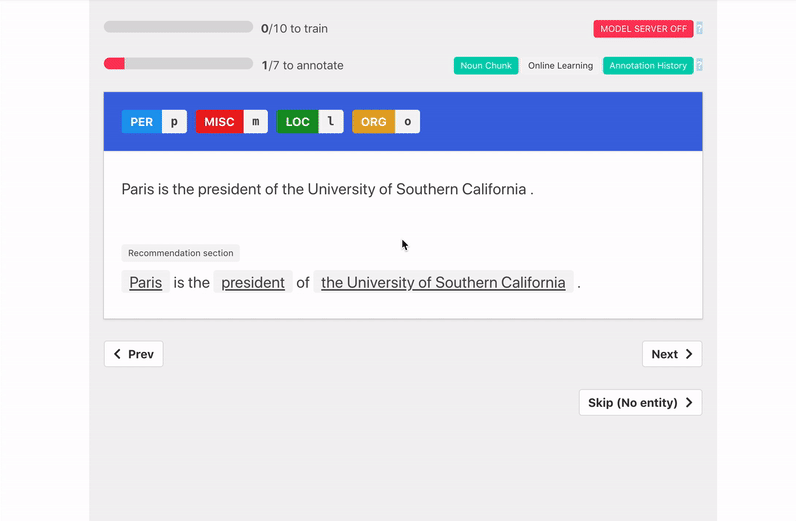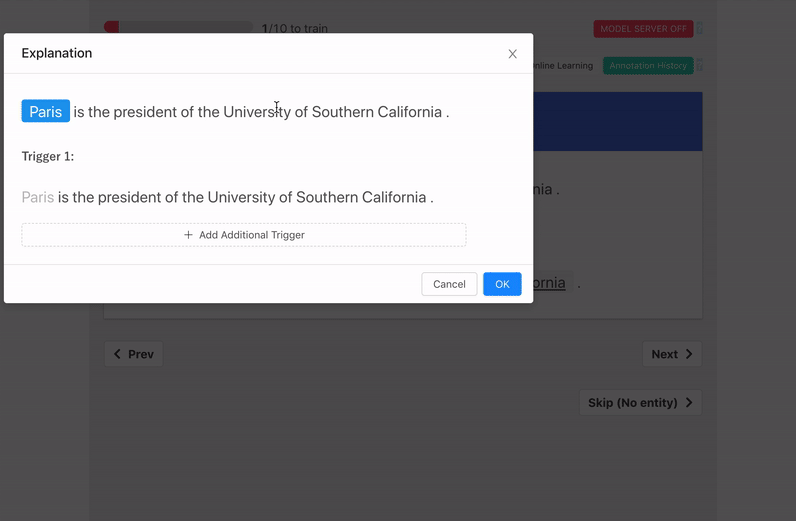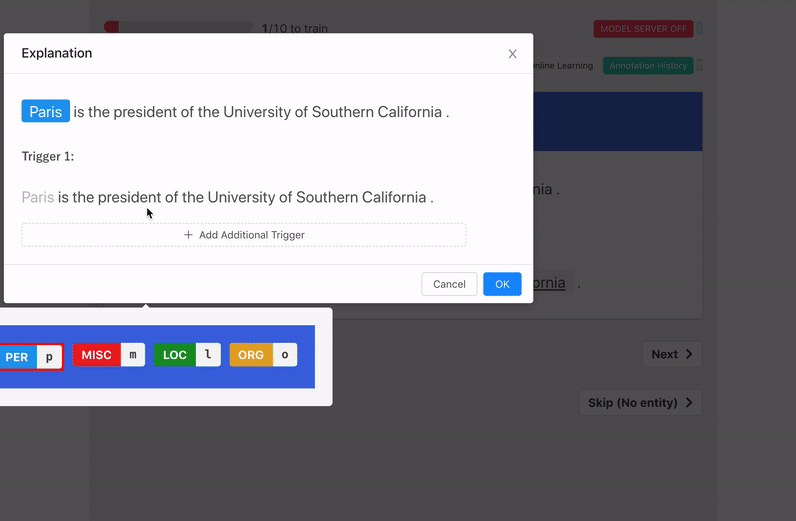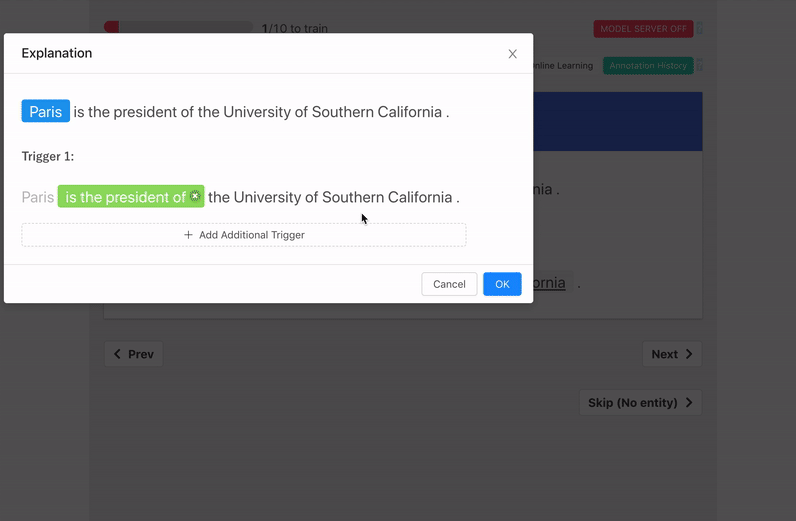
Train Model With Explanations

"When starting with little to no labeled data, it is more effective to ask annotators to provide a label and an explanation for the label, than to just request a label."
To cite us
@inproceedings{lee-etal-2020-lean,
title = "{LEAN}-{LIFE}: A Label-Efficient Annotation Framework Towards Learning from Explanation",
author = "Lee, Dong-Ho and
Khanna, Rahul and
Lin, Bill Yuchen and
Lee, Seyeon and
Ye, Qinyuan and
Boschee, Elizabeth and
Neves, Leonardo and
Ren, Xiang",
booktitle = "Proceedings of the 58th Annual Meeting of the Association for Computational Linguistics: System Demonstrations",
month = jul,
year = "2020",
address = "Online",
publisher = "Association for Computational Linguistics",
url = "https://www.aclweb.org/anthology/2020.acl-demos.42",
pages = "372--379"}