🪨 RockNER: A Simple Method to Create Adversarial Examples for Evaluating the Robustness of NER Models
✍️ Bill Yuchen Lin, Wenyang Gao, Jun Yan, Ryan Moreno, Xiang Ren
🏢 in Proceedings of EMNLP 2021 (short)

Quick Links
Paper Github OntoRock Dataset Leaderboard
Intro
To audit the robustness of named entity recognition (NER) models, we propose RockNER, a simple yet effective method to create natural adversarial examples. Specifically, at the entity level, we replace target entities with other entities of the same semantic class in Wikidata; at the context level, we use pre-trained language models (e.g., BERT) to generate word substitutions. Together, the two levels of at- tack produce natural adversarial examples that result in a shifted distribution from the training data on which our target models have been trained. We apply the proposed method to the OntoNotes dataset and create a new benchmark named OntoRock for evaluating the robustness of existing NER models via a systematic evaluation protocol. Our experiments and analysis reveal that even the best model has a significant performance drop, and these models seem to memorize in-domain entity patterns instead of reasoning from the context. Our work also studies the effects of a few simple data augmentation methods to improve the robustness of NER models.
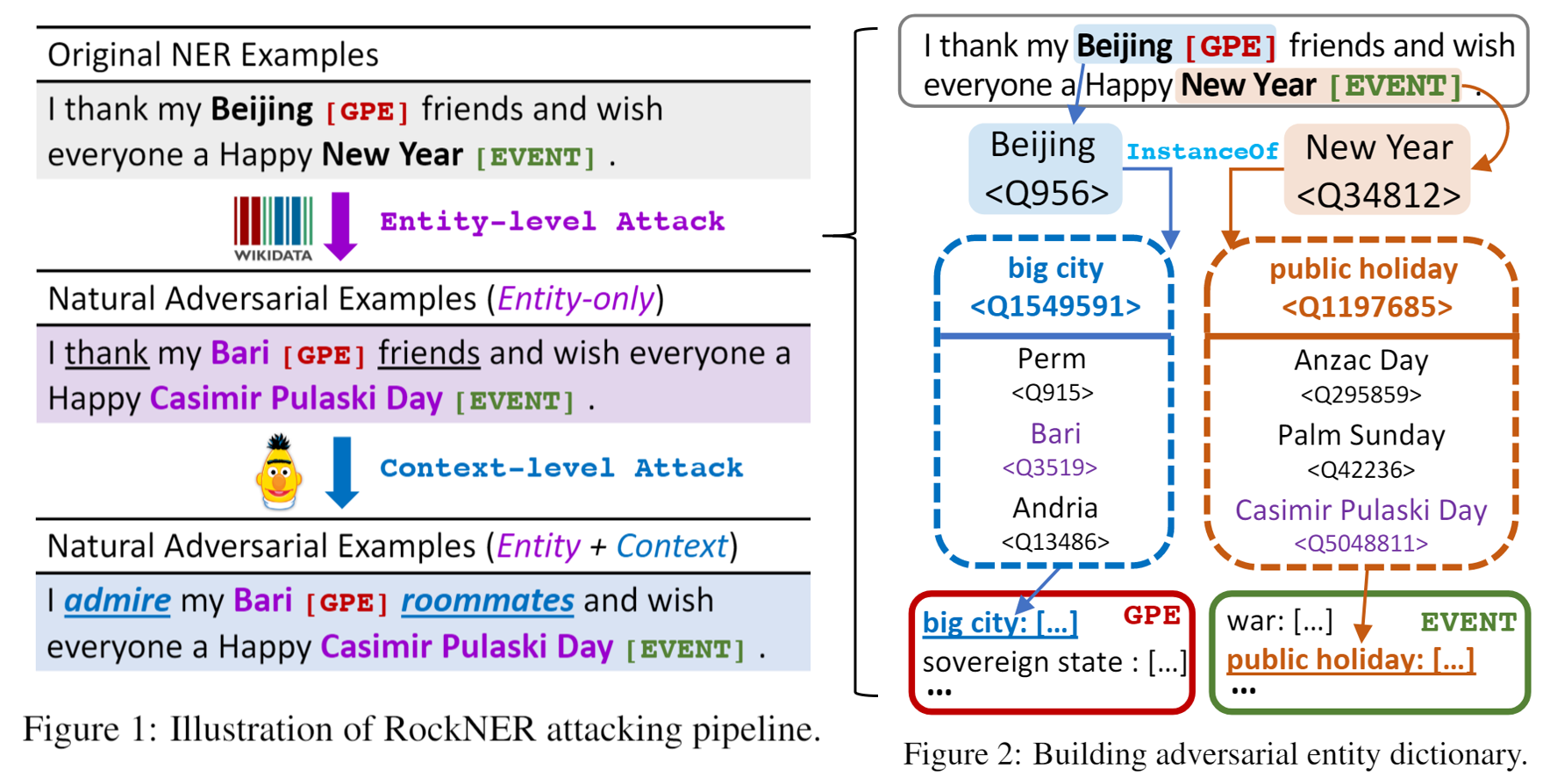
Dataset Format
Please download our OntoRock dataset by filling the form here and the link will show up once you read the disclaimer and submit it. There are eight files as follows:
Original-OntoNotes_train.txt(1,148,427 lines)- The original training data of OntoNotes.
OntoRock-Full_dev.txt(161,123 lines)- The development data of OntoRock-Full.
OntoRock-Entity_dev.txt(161,152 lines)- The development data of OntoRock-Entity.
OntoRock-Context_dev.txt(156,215 lines)- The development data of OntoRock-Context.
Original-OntoNotes_test_pub.txt(160,989 lines)- The original test data of OntoNotes, where the truth tags are hidden.
OntoRock-Full_test_pub.txt(165,872 lines)- The test data of OntoRock-Full, where the truth tags are hidden.
OntoRock-Entity_test_pub.txt(165,906 lines)- The test data of OntoRock-Entity, where the truth tags are hidden.
OntoRock-Context_test_pub.txt(160,953 lines)- The test data of OntoRock-Context, where the truth tags are hidden.
# a sentence in our txt file, truth tags are hidden in test files
We O
respectfully O
invite O
you O
to O
watch O
a O
special O
edition O
of O
Across B-ORG
China I-ORG
. O
# sentences are separated by blank line
Leaderboard
| Model | Submitter | Ori_test_F1 | OntoRock_test_F1 | ||
|---|---|---|---|---|---|
| Ent | Cont | Full | |||
| RoBERTa-CRF | USC-INK | 92.4 | 63.4 | 87.2 | 58.5 |
| Flair | USC-INK | 90.7 | 59.6 | 86.1 | 55.3 |
| BERT-CRF | USC-INK | 90.6 | 59.2 | 85.8 | 54.6 |
| Stanza | USC-INK | 87.9 | 56.1 | 83.0 | 51.7 |
| Spacy | USC-INK | 87.3 | 43.9 | 81.8 | 40.1 |
| BLSTM-CRF | USC-INK | 84.6 | 40.5 | 77.3 | 32.4 |
Submission Guide
Please submit your prediction file (as the same format above — 1st column for tokens and 2nd column for predicted tags) and information via this site.
Citation
@inproceedings{lin-etal-2021-rockner,
title = "RockNER: A Simple Method to Create Adversarial Examples for Evaluating the Robustness of Named Entity Recognition Models",
author = "Lin, Bill Yuchen and Gao, Wenyang and Yan, Jun and Moreno, Ryan and Ren, Xiang",
booktitle = "Proc. of EMNLP (short paper)",
year = "2021",
note={to appear}
}