Overview

Explanations
Motivation & Example
Humans develop reading comprehension abilities efficiently by generalizing from only a few examples. When we see the following example,
Question: When was Queen Victoria’s funeral held?
Context: Her funeral was held on Saturday, 2 February, in St George’s Chapel, Windsor Castle, and after two days of lying-in-state …
Answer: Saturday, 2 February
We generalize this to a group of questions “When was sth. done?” and context “Sth. was done on [ANS].” We then know what to look for when seeing questions of similar type. In contrast, neural networks probably won’t capture this after seeing sufficient examples.
In light of this, we propose to teach reading comprehension ability by collecting semi-structured explanations that characterizes this generalization ability while being machine actionable. In the previous example, an explanation may look like this,
X is “funeral”. Y is “held”. In the question X is within 4 words after “when was” and Y is directly after X. “on” is directly before the answer. Y is within 2 words before the answer. X is within 3 words left of Y. The question starts with “when”, so the answer should be a date.
We parse and process explanations into runnable programs, which we call Neural Module Teachers. The program generated from the explanation above will be responsible for all “When was sth. done?” type of quesitons. For example,
Question: When was independence declared?
Context: … Independence was declared on 24 September 1973
Answer: 24 September 1973
Please find more examples in our Data Explorer page. You can also download all explanations that we use here.
Definition
In our study, explanations are semi-structured sentences describing why an answer is correct. They are comprised of two parts: variables and rules.
Variables are phrases that may be substituted in a question or answer when generalizing to unseen instances. e.g., X is “funeral”. Y is “held”. We request annotators to explicitly mark them explicitly.
Rules are statements that describe the characteristics of variables and relationships between them. The rules are first parsed into logical forms then transformed to executable functions. e.g., Y is within 2 words before the answer. In later steps, these rules will be parsed into its equivalent logcial form @Is(Y,@LessThan(@Left(Answer), 2) and final executable function (COMPARE(DISTANCE(Ans,FIND(Y)),2).
Method
Matching
When a new unlabeled instance matches the descriptions in an explanations, we give this instance a pseudo-label and use it for downstream training. We consider two types of matches: strict match and softened match. Strict match requires that every statement in the explanation is strictly satisfied, and this results in limited coverage for each explanation. Softened match, as implied by the name, soften its constraints in matching.
For example, if the explanation states “X is within 3 words left of Y” but in the current instance we found the distance to be 5, we consider this constraint is still “satisfied”, but with a confidence score (e.g., 0.9375). When Y is “declared” in the question, but “announced” (instead of “declared”) appear in the context, we also consider it a softened match. Softened matching is enabled with 4 modules of softening: Fill, Find, Compare, and Logic. For more details about matching, please go to this page.
Training
Now we have obtained some pseudo-labels on our unlabeled dataset. Formally, Sa denotes strictly-matched data, Sp denotes softly-matched data (with lower confidence), Su denotes the remaining unlabeled data. You can feed these data into your favorate reading comprehension model like BERT and ALBERT.
When we learn from softly-matched data, we use the confidence score to determine the weight for each instance. We also lower the weight in loss term for softly-matched data, since they’re potentially noisy. Please refer to the paper for more details.
Performance
Main Results
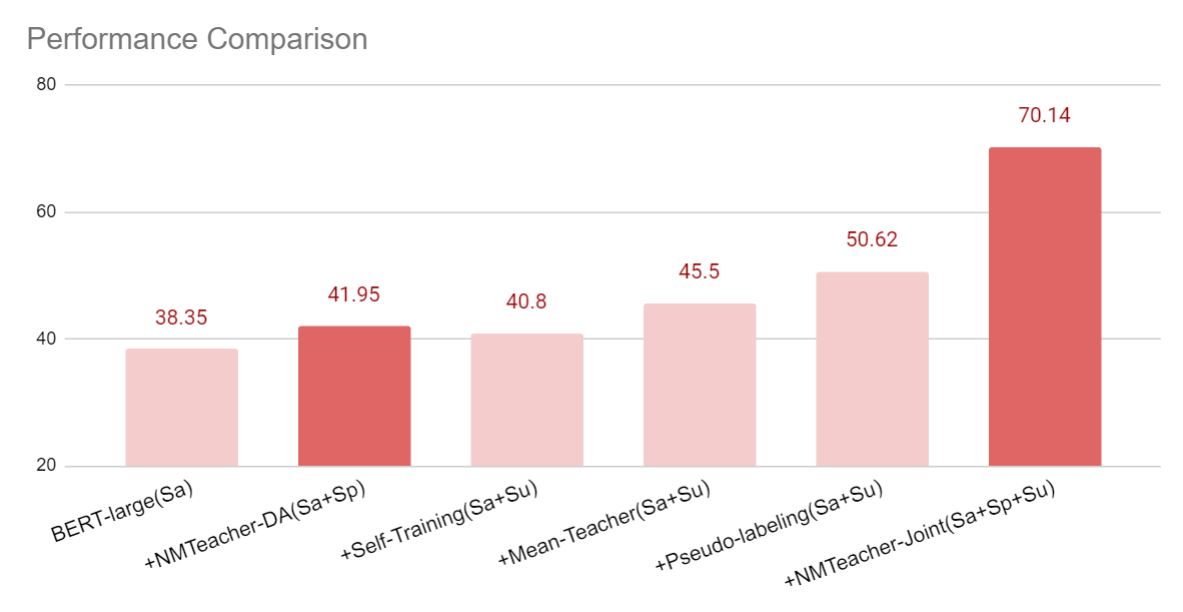
The baseline for each model uses as training the strictly-matched instances (Sa) generated using the explanations. For all models, performance then improves when we include the softly-matched instances (Sp). This method is denoted as NMTeacher-DA. In most cases, performance improves further when trained with semi-supervised learning and Su. Finally, performance is best when we make full use of Sa, Sp and Su, and jointly train the MRC model and the soft matching modules. This method is denoted as NMTeacher-Joint.
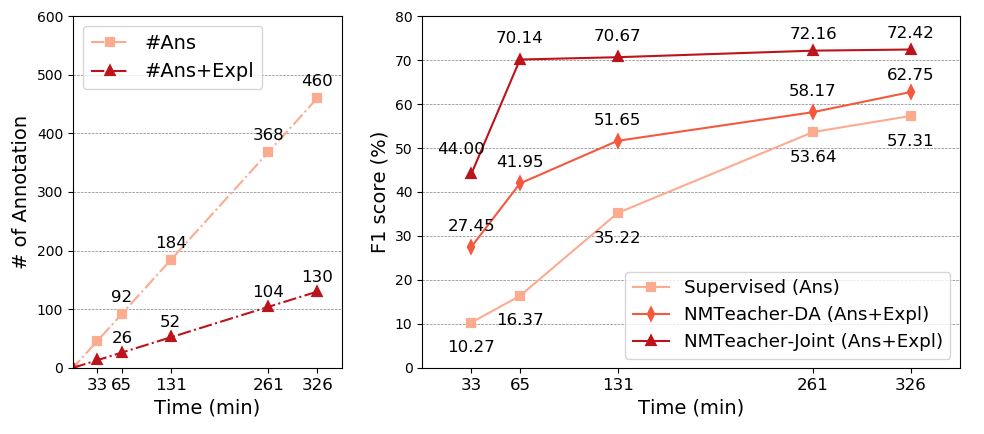
Efficiency Study
In our user study, one answer span annotation takes 43 seconds, while one answer span plus one explanation take 151 seconds (3.5x slower). We compare model performance when annotation time is held constant. NMTeacher-Joint consistently outperforms the baseline without explanations. For example, when using 65 minutes of annotation, 70.14% F1 on SQuAD is achieved by collection answer+explanation, while 16.37% F1 is achieved with answer span supervision. minutes of annotation).
Cite Us
@inproceedings{ye-etal-2020-teaching,
title = "Teaching Machine Comprehension with Compositional Explanations",
author = "Ye, Qinyuan and Huang, Xiao and Boschee, Elizabeth and Ren, Xiang",
booktitle = "Findings of the Association for Computational Linguistics: EMNLP 2020",
month = nov,
year = "2020",
address = "Online",
publisher = "Association for Computational Linguistics",
url = "https://www.aclweb.org/anthology/2020.findings-emnlp.145",
pages = "1599--1615",
}