Contextualizing Hate Speech Classifiers with Post-hoc Explanation
Brendan Kennedy, Xisen Jin, Aida Mostafazadeh Davani, Morteza Dehghani, Xiang Ren, ACL 2020.
Abstract
Hate speech classifiers trained on imbalanced datasets struggle to determine if group identifiers like "gay" or "black" are used in offensive or prejudiced ways. Such biases manifest in false positives when these identifiers are present, due to models' inability to learn the contexts which constitute a hateful usage of identifiers. We extract post-hoc explanations from fine-tuned BERT classifiers to detect bias towards identity terms. Then, we propose a novel regularization technique based on these explanations that encourages models to learn from the context of group identifiers in addition to the identifiers themselves. Our approach improved over baselines in limiting false positives on out-of-domain data while maintaining or improving in-domain performance.
Media posts: Context Reduces Racial Bias in Hate Speech Detection Algorithms. USC Viterbi | Unite.AI | Science Daily
Examples
Choose an example
Showing hierarchical explanations by SOC. Red indicates hate; blue indicates non-hate. Top level hierarchy indicates model predictions. Texts are sampled from New York Times articles; All ground truth labels are non-hate.
(a) SOC hierarchical explanation on BERT without regularization
(b) SOC hierarchical explanation on BERT with explanation regularization
Method Overview

We manually identify 25 group identifiers (e.g. jews, women) with top weights in a linear classifier. To discourage the models from making predictions solely by looking at the group identifiers, we extract SOC post-hoc explanation (Jin et al. 2020) on them alongside training. The explanation algorithm measures how group identifiers alone contribute to predictions given a training example. We penalize SOC explanations on group identifiers alongside training.
Experiments
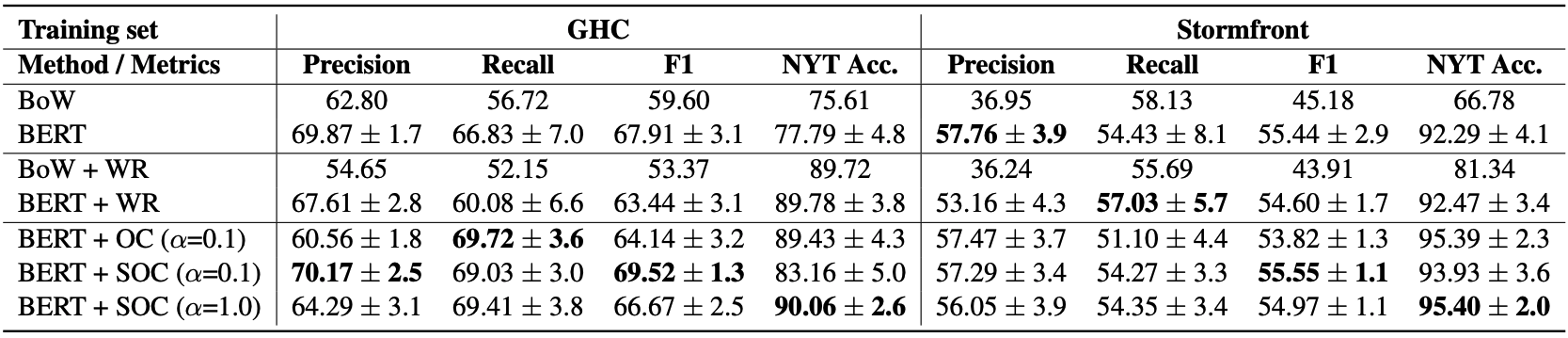
Datasets. We experiment with Gab Hate Corpus (GHC) corpus (Kennedy et al. 2020) and Stromfront (Stf) corpus (de Gibert et al. 2018). We also construct a test set of New York Times (NYT) articles that are filtered to contain a balanced, random sample of the twenty-five group identifiers, which are all non-hate examples.
Baselines. We compare performance between unregularized models (BERT), word-removal baseline (BERT+WR), and explanation regularization methods (BERT+OC, BERT+SOC), where we try different regularization strengths and post-hoc explanation algorithms.
Results. We report in-domain precision, recall, F1 and out-of-domain accuracy on NYT corpus. Our explanation regularization methods significantly reduce false positives on NYT corpus compared to unregularized BERT, while maintain or improve in-domain performance .
To cite us
@inproceedings{kennedy2020contextualizing,
author = {Kennedy*, Brendan and Jin*, Xisen and Mostafazadeh Davani, Aida and Dehghani, Morteza and Ren, Xiang},
title = {Contextualizing {H}ate {S}peech {C}lassifiers with {P}ost-hoc {E}xplanation},
year = {to appear},
booktitle = {Proceedings of the 58th {A}nnual {M}eeting of the {A}ssociation for {C}omputational {L}inguistics}
}